2. How JQM works¶
2.1. Basic JQM concepts¶
The goal of JQM is to launch payloads, i.e. Java code doing something useful, asynchronously. This code can be anything - a shell program launcher, a Spring batch, really anything that works with Java SE and libraries provided with the code.
The payload is described inside a job definition - so that JQM knows things like the class to load, the path of the jar file if any, etc. It is usually contained within an XML file. The job definition is actually a deployment descriptor - the batch equivalent for a web.xml or an ejb-jar.xml.
A running payload is called a job instance (the “instance of a job definition”). These instances wait in queues to be run, then are run and finally archived. To create a job instance, a job request is posted by a client. It contains things such as optional parameters values, but most importantly it specifies a job definition so that JQM will know what to run.
Job instances are run by one or many engines called JQM nodes. These are simply Java processes that poll the different queues in which job instances are waiting. Runs take place within threads, each with a dedicated class loader so as to fully isolate them from each others (this is the default behaviour - class loader sharing is also possible).
Full definitions are given inside the Glossary.
2.2. General architecture¶
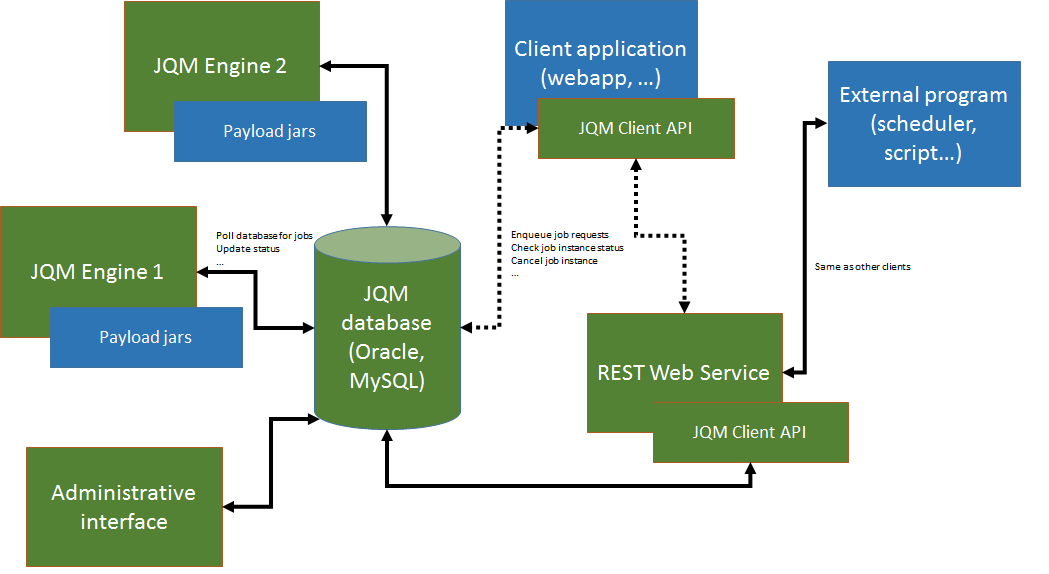
On this picture, JQM elements are in green while non-JQM elements are in blue.
JQM works like this:
- an application (for example, a J2EE web application but it could be anything as long as it can use a Java SE library) needs to launch an asynchronous job
- it imports the JQM client (one of the two - web service or direct-to-database. There are two dotted lines representing this choice on the diagram)
- it uses the ‘enqueue’ method of the client, passing it a job request with the name of the job definition to launch (and potentially parameters, tags, ...)
- a job instance is created inside the database
- engines are polling the database (see below). One of them with enough free resources takes the job instance
- it creates a dedicated class loader for this job instance, imports the correct libraries with it, launches the payload inside a thread
- during the run, the application that was at the origin of the request can use other methods of the client API to retrieve the status, the advancement, etc. of the job instance
- at the end of the run, the JQM engine updates the database and is ready to accept new jobs. The client can still query the history of executions.
It should be noted that clients never speak directly to a JQM engine - it all goes through the database.
Note
There is one exception to this: when job instances create files that should be retrieved by the requester, the ‘direct to database’ client will download the files through a direct HTTP GET call to the engine. This avoids creating and maintaining a central file repository. The ‘web service’ client does not have this issue as it always uses web services for all methods.
2.3. Nodes, queues and polling¶
As it names entails, JQM is actually a queue manager. As many queues as needed can be created. A queue contains job instances waiting to be executed.
To get a JQM node to poll a queue, it is necessary to associate the node with the queue. The association specifies:
- The node which should poll
- The queue which should be polled
- The maximum number of job instances the node should be able to run at the same time for this queue (a maximum thread count)
- The polling interval (minimum is 1 second to spare the poor database). This is the time between two requests to the queue. On each request, the node will try to fill up its maximum number of job instances (if the maximum is three concurrent job instances and nothing is running yet, the node will ask for three jobs on each loop).
By default, when creating the first engine, one queue is created and is tagged as the default queue (meaning all jobdef that do not have a specific queue will end on that one). All further new nodes will have one association created to this default queue.
With this way to associate queue to nodes, it is very easy to specialise nodes and usages. It is for example possible to have one node polling a queue very fast, while another polls it more slowly. More interestingly, it makes it easy to adapt to the size of the underlying servers: one engine may be able to run 10 jobs for a queue in parallel while another, on a more powerful server, may run 50 for the same queue. It also makes it possible to specialise servers: some will poll a set of queues, others will poll a completly different set of queues.
A Job Definition has a default queue: all job requests pertaining to a job definition are created (unless otherwise specified) inside this queue. It is possible at job request submission, or later once the job instance waits inside its queue, to move a job instance from one queue to another as long as it has not already began to run.
An example:
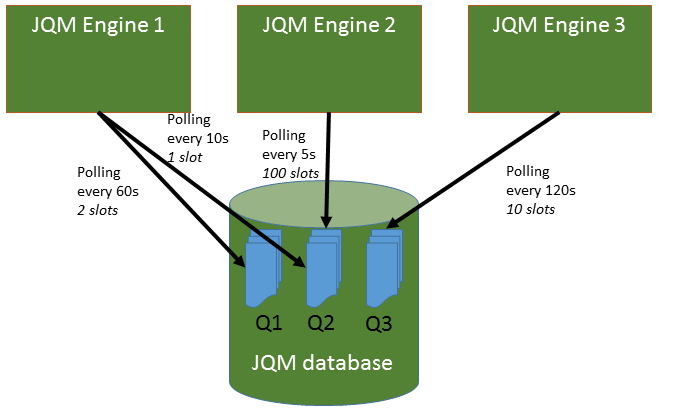
Here, there are three queues and three engine nodes inside the JQM cluster. Queue 1 is only polled by engine 1. Queue 3 is only polled by engine 3. But queue 2 is polled both by engine 1 and engine 2 at different frequencies. Engine 2 may have been added because there was too much wait time on queue 2 (indeed, engine 1 only will never run more than one job instance at the same time for queue 2 as it has only one slot. Engine 2 has 100 so with both engines at most 101 instances will run for queue 2).
2.4. Job Instance life-cycle¶
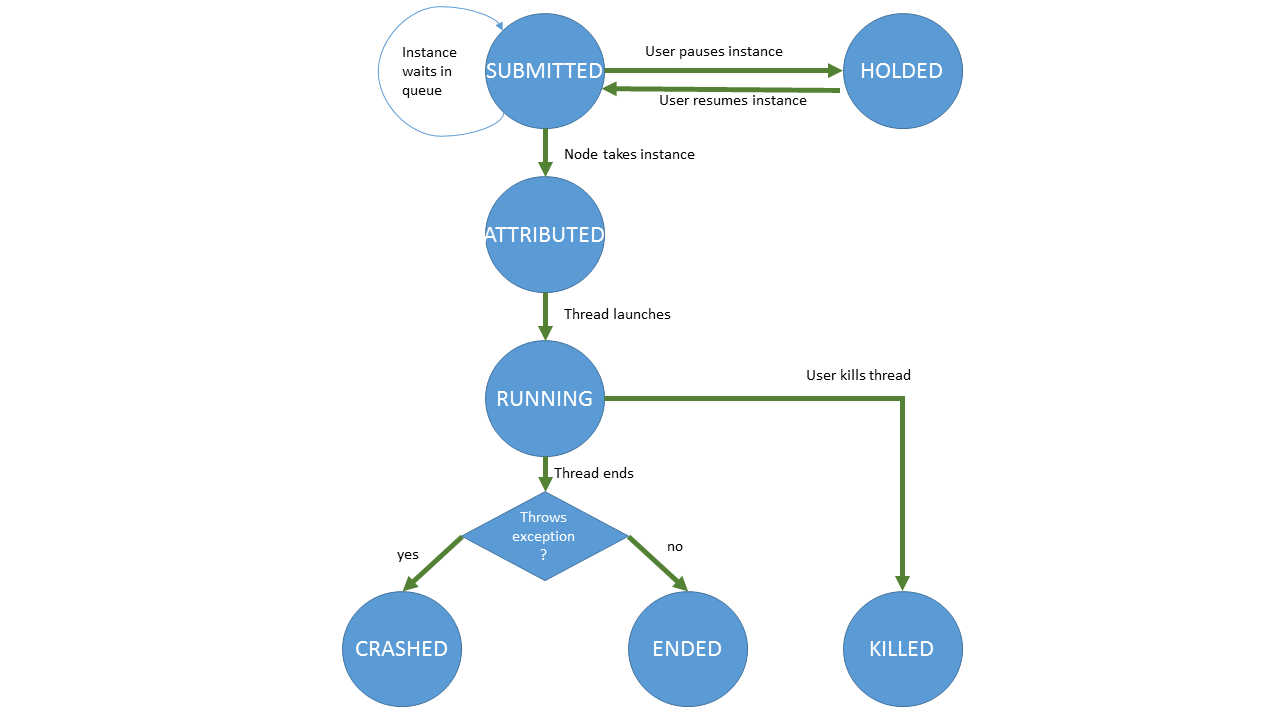
This represents all the states a job instance goes through. The diagram is self explanatory, but here are a few comments:
- The first state, SUBMITTED, happens when a job request is submitted hence its name. It basically is a “waiting in queue” state.
- The ATTRIBUTED state is transient since immediately afterwards the engine will launch the thread representing the running job (and the instance will take the RUNNING state). Engines never take in instances if they are unable to run it (i.e. they don’t have free slots for this queue) so instances cannot stay in this state for long. It exists to signal all engines that a specific engine has promised to launch the instance and that no one else should try to launch it while it prepares the launch (which takes a few milliseconds).